#tcp handshake
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text

(x)
thank you to averyluckyclover for letting me do this silly edit

random noise to let you know I love u
45K notes
·
View notes
Text
The three-way handshake, also known as the TCP handshake, is a method used in network communication protocols, particularly in the TCP (Transmission Control Protocol). It involves the exchange of three distinct messages between the client and server to guarantee a secure and synchronized connection before data transmission begins.
#tcp#ip#three way handshake#transmission control protocol#network communication#infosectrain#learntorise
0 notes
Text

Just two androids partaking in an ancient ritual of TCP handshaking, invented in the 1970’s
#dbh#androids#you think they are shaking hands while they exchange gigabites worth of data right in front of your eyes#while you think exchanging fluids is as intimate as it gets those mfs are reliving their memories together
15 notes
·
View notes
Note
give me violence pls and ty; 6, 7, 19 & 20
questions here ty for the ask I love people immediately came into my inbox to ask me to complain about canon y'all know me so well
6. which ship fans are the most annoying?
I'm not really annoyed by any particular ship, more so people who complain about other shippers not doing it right- and specifically if they put it in the character tags.
also anyone who has gone through silverv tags and forced me to add a nonbinary tag to my stuff because they a) assume that she/her pronouns mean a woman and b) are apparently obliged by their tagging system to distinguish between female and male v. c'mon man. it's only happened twice but that was enough.
7. what character did you begin to hate not because of canon but because how how the fandom acts about them?
idk about *hate* exactly but Rogue, I guess? she so often seems to be either a mommy character to people's v's or people talk about how tragic she is for liking johnny, which I don't understand. she doesn't seem to be very nurturing and it's pretty clear she's got a soft spot for johnny but given she's lived to be 90 doing merc work I think she can take care of and make decisions for herself that are "bad" without being pitied for it? it's not like johnny is manipulating her. he asks and she says yes even though she's dumped him to the curb and could easily walk away or refuse. anyway I don't hate rogue, I just don't see a lot of her, and the characterization I do see I'm lukewarm on.
19. you're mad/ashamed/horrified you actually kind of like...
I had the usual cyberpunk experience of wanting to stick Johnny's head in the toilet and then he grew on me, so now every time I see him I still want to physically fight him but like in an affectionate way. So embarrassing.
Also: Smasher?? Like he still terrifies me, but what a character! He's a brain in a tin can and all he wants to do is perform violence, and unlike most of the other lore in game (cyberware will make you crazy!!) he's been Like That since he was 100% organic. There's just something wrong with him that makes him immune to bodily concerns and Arasaka keeps him like a literal attack dog they can use to scare people. He has such a clarity of purpose. He has a body that looks like Elvis. He used to talk in a southern accent. I think he should live forever.
20. part of canon you found tedious or boring
there are lots of AIs that are all FERAL and EVIL in the cage and they're going to come get you. now hold on while we act out the TCP handshake in 3D with visuals that make your eyes hurt that apparently people are working in all day because abstractions make tech COOL and ENGAGING. we have the tech to mess with people's memories and upload their souls but these AIs are ALL POWERFUL and in fifty years we haven't found the servers they're squatting on. the only one you can make contact with used to be HUMAN but all the rest are definitely BAD and MAD and INSANE. also they can insta-kill people or possess killer robots. this fits perfectly in the cyberpunk theme of um uh. technology has gone too far? people are at their fucking limit?
I forget exactly what scifi writer talked about it and it's impossible to google "AI anxiety" in tyool 2024 and get anything but people concerned ChatGPT is sentient, but there's this idea that the scifi story anxiety about AI rebellions or robots killing all humans is basically repackaged anxiety that people who have been stepped on or used or enslaved are going to suddenly fight back and kill everyone is not a new one. It's just "ah the oppressed are dangerous because some day they will want revenge". These AIs are super smart and powerful but they're not going to have the sentience to recognize allies? They just kill indiscriminately? They're no better than monsters? Alright. Maybe the sequel will surprise me and get into some nuance but I'm distrustful by nature.
#ALSO soulkiller and being digitized is like a very interesting philosophical discussion#but the game pretty much presents it one way if the topic is ever brought up#as though the continuity of self and multiple copies isn't fascinating#I guess I've got another ask with which to ramble about the shit going on in mikoshi#TY for these questions :3#answered ask#ask game
4 notes
·
View notes
Text
I may be new to tumblr, but I already have a ton of stupid phrases saved up that I can repost here. For example:
Are you a TCP handshake? Because you're a syn+ack
I think posting random shower thoughts is how tumblr works, I just haven't figured out the etiquette around using punctuation
2 notes
·
View notes
Text
remembered that the other day i was thinking about how like, "jared & alana kind of re/connecting more in college / becoming friends then" ideas sure have a potential complication in "do they talk about tcp ever lol. jared has this secret here" where like yeah maybe the answer is "no not really," at this point post orchard it can be kind of in the past / in stasis, like maybe alana keeps the site up & all but for one thing, well, she's busy with college at the moment & maybe even other things (so many possibilities about what college looks like for alana or jared or whomever. just like in life) and also from her perspective like well jared wasn't ever That involved anyways, even if you harmonized together for two measures in a song like of course alana was focused on evan as the other co president co True Believer / Understander about the ethos of the project anyways, vs that it was fine to have jared in the background possibly, doing tech support. and she could just suppose that, even if she does suspect something Was up about everything, that maybe it's not like jared knew about that or was involved
but anyways i was like "well fuck it, what if she did also suspect jared could've known anything was up about the supposed factual premises around here. and she was mostly fine with that" (which i mean. could be true anyways. alana could sure likewise just have complicated feelings, about things beyond The Absolute Facts Of The Case, as is relevant the entire time re: anyone else. even if yeah it would also bother her. she has her own path right there to sympathizing more easily anyways in like, yeah she Was his lab partner, the facts may not be that moving, but it was still meaningful enough to her as a connection / Theoretical connection like 'well we Could've been friends?' / alana sympathizing with someone Now Never Having The Chance To Know Connor which is also evan's status or anyone else's anyways)
so further anyways i was also just thinking how like, well, there's complications in "jared can't tell the full story b/c a) he & evan are keeping this secret for themselves And each other, just unspoken across time & space & perhaps forever thusly. nbd & b) he can't tell the Full Story to anyone else anyways. goodforyou.mp3....though, see: the Handshake Gay potential element to college alana & jared friendship lol. don't need to give granular details about Realizing Things / Fun Facts of disastrous [all very heterosexual] relationship histories" but also maybe even if he is willing to give any very general acknowledgment to "Was something up with all that, do you think, do you know" type inquiries, it was like well but what if that's actually somewhat / enough of a relief to alana to get further confirmation that yeah there were some extra reasons things fell apart a bit there. Because like, otherwise, from her perspective it's like she was helming this surely noble helpful project with mostly this one other person who then stopped caring or at least responding in the same ways, and then that happened more generally with alana being mostly solo running things and then those things going to shit. where maybe having a hint that yeah, there was some other weird complications going on like problems as fundamental as [this story wasn't quite factually true was it] can be, to her, like nonzero reassurance that She Herself wasn't thee factor who like managed to be on a different page than everyone else after all & also just ruin things in whatever way b/c it was all going great until it sure wasn't
#deh#the complication becoming like ''can jared give some Vague responses that in their ambiguity don't suggest he also only Suspects vs like#yeah he Knows something was up'' but like he can also just stop being so Responsive any further than that#like [we must Investigate this] (which like. is hardly a response alana would guaranteed have in turn) well jared can just: Not#even without giving more info about Why not. easy to avoid being dragged into that. just don't do anything. shrug. homework time#anyways. like just a strange situation overall i think they can handle the weirdness of ''yeah jared Is withholding further info but''#like Okay & the idea here being that alana Could actually just be glad to get whatever tilt of the head is like yeah....#neither me nor the facts were quite straight were they pensive emoji....#b/c again like tl;dr confirmation that she didn't / doesn't Ruin any efforts at helping ppl b/c of something just about her & her efforts#neither does she have to feel oh i did everything Perfectly b/c how would that be helpful for any of the characters#or for anyone ever in any situation. but again if instead she thinks oh evan Was the grieving bestie the story Was true etc etc....#like well then seems Your involvement & [being the main person making tcp a thing & then keeping it a thing] messed that up
5 notes
·
View notes
Text
Yeah, it's probably an automatic call/response ping. That's how computers on a network locate and identify each other.
In TCP/IP computers use a 3-way handshake to establish a connection before they start communicating. The initiating PC sends a sync request [SYN] containing the IP and port of the source, and the intended IP and port of the destination. the server/second pc sees it and sends back and acknowledgement [SYN/ACK] confirming the details and responding with it's own information. Finally the initiating computer sends a final acknowledgement [ACK] confirming all of the details and opening a channel for communication. The process takes milliseconds.
If they're trying to hail another ship, they would be doing so using this same basic principle. If the other ship has all channels closed their SYN would be unanswered or perhaps rejected. In which case they would know in about 0.01 seconds that there's no response and the other ship isn't recieving their hails.
On the other hand, as has happened in a couple of episodes, if the other ship is receiving their hails and just choosing to ignore them, the 3 way handshake would work, the connection would be established, but all subsequent packets would simply be swallowed by the server with no echo. This would present as CPT. Picard repeatedly introducing himself and the other captain not answering.
one of my pettiest complaints about star trek is that they always say “hailing [the other ship]” and then 0.3 seconds later say “no response” as though they’re meant to have had time to even register they’re being hailed let alone RESPOND
35K notes
·
View notes
Text
How LiteSpeed Improves Loading Speed
Website speed is a critical factor in user experience, SEO performance, and conversion rates. Faster-loading websites engage visitors better, reduce bounce rates, and rank higher in search results. LiteSpeed Web Server (LSWS) is engineered to optimize website speed with powerful technologies built into its core. This article provides a technical and practical look at how LiteSpeed improves website performance, its architectural strengths, and comparisons with other web servers like Apache and NGINX.
What Is LiteSpeed?
LiteSpeed is a high-performance web server software developed by LiteSpeed Technologies. It serves as a drop-in replacement for Apache, meaning it can use Apache configurations such as .htaccess and mod_rewrite while offering far superior performance.

Unlike traditional web servers that rely on process-based or thread-based architectures, LiteSpeed uses an event-driven approach. This enables it to handle thousands of simultaneous connections efficiently without consuming excessive resources. It’s widely used in shared, VPS, and dedicated hosting environments due to its scalability and speed.
LiteSpeed is compatible with major web hosting control panels like cPanel, Plesk, and DirectAdmin. It also integrates seamlessly with WordPress, Magento, Joomla, and other popular CMS platforms.
How LiteSpeed Improves Loading Speed
LiteSpeed's performance is not just theoretical. Numerous benchmarks and case studies show significant improvements in load time, server response, and concurrent user handling. Its technical foundation plays a pivotal role in enabling these advantages.

Event-Driven Architecture
Most traditional web servers like Apache use a process-based or threaded architecture. Each connection requires a dedicated process or thread, which leads to high memory usage under load.
LiteSpeed uses an event-driven, asynchronous model. It processes multiple connections within a single thread, significantly reducing memory consumption and CPU load.
For example, benchmarks by LiteSpeed Technologies show that LSWS handles over 2x more concurrent connections than Apache with the same hardware configuration [1]. This architecture is especially beneficial during traffic spikes, such as flash sales or viral content events.
Built-In Caching (LSCache)
LiteSpeed’s caching engine, LSCache, is built directly into the server core. Unlike third-party caching plugins that operate at the application level, LSCache works at the server level, making it faster and more efficient.
With LSCache enabled on WordPress, testing from WPPerformanceTester shows up to 75% reduction in page load times compared to uncached sites. This is because LSCache delivers prebuilt HTML pages directly to users, bypassing PHP execution and database queries.
LSCache also supports advanced features such as:
ESI (Edge Side Includes) for partial page caching
Smart purging rules
Private cache for logged-in users
Image optimization and critical CSS generation
These features make it suitable not only for static pages but also for dynamic, eCommerce-heavy platforms like WooCommerce or Magento.
Compression and Optimization
LiteSpeed supports GZIP and Brotli compression out of the box. These technologies reduce the size of files transmitted over the network, such as HTML, CSS, and JavaScript.
According to Google PageSpeed Insights, compressing assets can reduce page size by up to 70%, which directly improves load time. Brotli, developed by Google, provides even better compression rates than GZIP in many cases, and LiteSpeed uses it efficiently.
Additionally, LiteSpeed can minify JavaScript, CSS, and HTML, combine files to reduce HTTP requests, and enable lazy loading for images—all directly from the server level.
QUIC and HTTP/3 Support
LiteSpeed is one of the earliest web servers to fully support QUIC and HTTP/3, protocols developed by Google and later adopted by IETF.
QUIC is built on UDP instead of TCP, which reduces handshake latency and improves performance over poor network conditions. HTTP/3 inherits QUIC’s benefits and introduces faster parallel requests and better encryption handling.
When HTTP/3 is enabled, page loads feel snappier, especially on mobile devices and in regions with weaker connectivity. Cloudflare reported up to 29% faster page loads using HTTP/3 versus HTTP/2 [2].
LiteSpeed’s implementation ensures that your site is future-ready and delivers optimal performance even under challenging network environments.
LiteSpeed vs Apache and NGINX
Performance benchmarks consistently show that LiteSpeed outperforms both Apache and NGINX in various scenarios, especially under high traffic and dynamic content conditions.

Apache Comparison
Apache is widely used but is resource-heavy under load. When serving PHP applications like WordPress, Apache relies on external modules (e.g., mod_php) or handlers like PHP-FPM, which increase overhead.
LiteSpeed replaces these with LiteSpeed SAPI, a more efficient PHP handler. Benchmarks show that LiteSpeed can process 3x more PHP requests per second compared to Apache [3].
NGINX Comparison
NGINX is known for its speed with static files, but it lacks full .htaccess compatibility and requires more manual tuning for dynamic sites.
LiteSpeed combines Apache’s ease of configuration with NGINX’s speed and goes further by offering built-in caching and QUIC support. This makes it a more all-in-one solution for both static and dynamic content delivery.
Real-World Results
A hosting provider, NameHero, migrated over 50,000 sites from Apache to LiteSpeed. The result was an average decrease in load time by 40%, with no change in hardware configuration [4].
Another example is a WooCommerce store that used LiteSpeed Cache. Load times dropped from 4.2s to 1.2s after activation, significantly improving Core Web Vitals and user retention.
Website owners consistently report faster Time to First Byte (TTFB), better PageSpeed scores, and fewer server crashes during traffic peaks when using LiteSpeed.
Who Should Use LiteSpeed?
LiteSpeed is ideal for:
WordPress users who want faster page loads without complex configurations.
WooCommerce and Magento store owners needing efficient dynamic caching.
Web hosting providers looking to reduce server load and increase client satisfaction.
SEO-focused marketers who want better Core Web Vitals.
Developers who want Apache compatibility with modern performance.
LiteSpeed is available in both open-source (OpenLiteSpeed) and commercial versions. While OpenLiteSpeed is suitable for smaller projects, the enterprise version offers advanced features and full control panel integration.
Final Thoughts
LiteSpeed offers a clear performance advantage due to its architecture, built-in caching, modern protocol support, and optimization features. It helps websites load faster by minimizing server load, reducing latency, and delivering content more efficiently.
Whether you're a developer, site owner, or hosting provider, switching to LiteSpeed can result in measurable improvements in speed, stability, and scalability. In today’s performance-driven web ecosystem, LiteSpeed is a practical solution backed by real results and advanced engineering.
1 note
·
View note
Text
How Alltick’s WebSocket API Crushes REST for High-Frequency Crypto Trading
How Alltick’s WebSocket API Crushes REST for High-Frequency Crypto Trading
The $4,300 Latency Tax
On May 12, 2024, Bitcoin surged 9% in 37 seconds following a false ETF approval rumor. Traders using REST APIs saw prices update 3.2 seconds late—enough time for the market to move 4,300perBTC∗∗beforetheirordersexecuted.Meanwhile,∗∗AlltickWebSocketusers∗∗capturedtherallyfromthefirsttick,banking∗∗4,300perBTC∗∗beforetheirordersexecuted**.Meanwhile,∗∗AlltickWebSocketusers∗∗capturedtherallyfromthefirsttick,banking∗∗1.2M in under a minute**.
This isn’t luck—it’s physics. REST APIs are obsolete for real-time trading, and in this guide, we’ll dissect:
Why REST fails (with packet-level analysis)
How WebSockets dominate (benchmark data)
Step-by-step migration (REST → WebSocket in <50 lines of code)
REST vs. WebSocket – A Network-Level Showdown
Problem 1: Polling Delays (The "Refresh Button" Dilemma)
How REST Works: Your bot sends HTTP requests every 1-5 seconds, begging exchanges for updates.
Coinbase rate limits: 10 requests/second (bursts get banned).
Binance polling lag: 800ms median delay during volatility.
Real-World Impact:
May 2024 BTC Flash Pump: REST traders missed the first 4,200 orders because their last poll was 2.9 seconds old.
Problem 2: Data Inefficiency (90% Useless Traffic)
REST Responses Include:json复制{ "timestamp": "2024-05-20T12:00:00.000Z", "bids": [[ "30000.00", "1.2" ]], // Only this changes "asks": [[ "30001.00", "0.8" ]], "status": "ok", // Repeated every request "exchange": "binance" // Wasted bytes }
Result: 92% of REST payloads are redundant headers and metadata.
WebSocket Fix:json复制{ "b": [["30000.00", "1.2"]], "a": [["30001.00", "0.8"]] } // 12 bytes vs. 300+
Problem 3: Connection Overhead (TCP Handshake Hell)
REST Penalty: Each request requires:
TCP handshake (1 roundtrip)
TLS negotiation (2 roundtrips)
HTTP request/response (1 roundtrip)
Total latency: 200-400ms per poll even on fiber.
WebSocket Advantage:
Single connection stays open.
Zero handshakes after initial setup.
Persistent compression (e.g., permessage-deflate). Get started today: [alltick.co]
0 notes
Text
Fighting Cloudflare 2025 Risk Control: Disassembly of JA4 Fingerprint Disguise Technology of Dynamic Residential Proxy
Today in 2025, with the growing demand for web crawler technology and data capture, the risk control systems of major websites are also constantly upgrading. Among them, Cloudflare, as an industry-leading security service provider, has a particularly powerful risk control system. In order to effectively fight Cloudflare's 2025 risk control mechanism, dynamic residential proxy combined with JA4 fingerprint disguise technology has become the preferred strategy for many crawler developers. This article will disassemble the implementation principle and application method of this technology in detail.
Overview of Cloudflare 2025 Risk Control Mechanism
Cloudflare's risk control system uses a series of complex algorithms and rules to identify and block potential malicious requests. These requests may include automated crawlers, DDoS attacks, malware propagation, etc. In order to deal with these threats, Cloudflare continues to update its risk control strategies, including but not limited to IP blocking, behavioral analysis, TLS fingerprint detection, etc. Among them, TLS fingerprint detection is one of the important means for Cloudflare to identify abnormal requests.
Technical Positioning of Dynamic Residential Proxy
The value of Dynamic Residential Proxy has been upgraded from "IP anonymity" to full-link environment simulation. Its core capabilities include:

JA4 fingerprint camouflage technology dismantling
1. JA4 fingerprint generation logic
Cloudflare JA4 fingerprint generates a unique identifier by hashing the TLS handshake features. Key parameters include:
TLS version: TLS 1.3 is mandatory (version 1.2 and below will be eliminated in 2025);
Cipher suite order: browser default suite priority (such as TLS_AES_256_GCM_SHA384 takes precedence over TLS_CHACHA20_POLY1305_SHA256);
Extended field camouflage: SNI(Server Name Indication) and ALPN (Application Layer Protocol Negotiation) must be exactly the same as the browser.
Sample code: Python TLS client configuration

2. Collaborative strategy of dynamic proxy and JA4
Step 1: Pre-screening of proxy pools
Use ASN library verification (such as ipinfo.io) to keep only IPs of residential ISPs (such as Comcast, AT&T); Inject real user network noise (such as random packet loss rate of 0.1%-2%).
Step 2: Dynamic fingerprinting
Assign an independent TLS profile to each proxy IP (simulating different browsers/device models);
Use the ja4x tool to generate fingerprint hashes to ensure that they match the whitelist of the target website.
Step 3: Request link encryption
Deploy a traffic obfuscation module (such as uTLS-based protocol camouflage) on the proxy server side;
Encrypt the WebSocket transport layer to bypass man-in-the-middle sniffing (MITM).
Countermeasures and risk assessment
1. Measured data (January-February 2025)

2. Legal and risk control red lines
Compliance: Avoid collecting privacy data protected by GDPR/CCPA (such as user identity and biometric information); Countermeasures: Cloudflare has introduced JA5 fingerprinting (based on the TCP handshake mechanism), and the camouflage algorithm needs to be updated in real time.
Precautions in practical application
When applying dynamic residential proxy combined with JA4 fingerprint camouflage technology to fight against Cloudflare risk control, the following points should also be noted:
Proxy quality selection: Select high-quality and stable dynamic residential proxy services to ensure the effectiveness and anonymity of the proxy IP.
Fingerprint camouflage strategy adjustment: According to the update of the target website and Cloudflare risk control system, timely adjust the JA4 fingerprint camouflage strategy to maintain the effectiveness of the camouflage effect.
Comply with laws and regulations: During the data crawling process, it is necessary to comply with relevant laws and regulations and the terms of use of the website to avoid infringing on the privacy and rights of others.
Risk assessment and response: When using this technology, the risks that may be faced should be fully assessed, and corresponding response measures should be formulated to ensure the legality and security of data crawling activities.
Conclusion
Dynamic residential proxy combined with JA4 fingerprint camouflage technology is an effective means to fight Cloudflare 2025 risk control. By hiding the real IP address, simulating real user behavior and TLS fingerprints, we can reduce the risk of being identified by the risk control system and improve the success rate and efficiency of data crawling. However, when implementing this strategy, we also need to pay attention to issues such as the selection of agent quality, the adjustment of fingerprint disguise strategies, and compliance with laws and regulations to ensure the legality and security of data scraping activities.
0 notes
Text
youtube
CCNA Course - Day 5 Transport Layer in OSI - TCP and UDP | 3 Way Handshake Process
#ping#internetworkingdevices#Switch#ICMP#datalinklayer#framing#mac#macaddress#hub#bridge#collision#Applicationlayer#networklayer#icmp#ccna#ccnacourse#ccnaclasses#ccnatraining#ccna200-301#ccnaonline#routing#switches#switching#router#routingprotocols#vlan#trunking#dtp#stp#Spanningtree
0 notes
Text
Troubleshooting Common Network Load Balancer Issues
Troubleshooting Common Network Load Balancer Issues focuses on identifying and resolving frequent problems that affect the performance and reliability of network load balancers (NLBs). Common issues include incorrect load balancing algorithms, misconfigured security groups or firewall settings, and improper health check configurations, which can cause traffic distribution errors or downtime. Addressing issues such as SSL/TLS handshake failures, DNS resolution problems, or server unavailability is also key to ensuring optimal operation. The blog will guide users through diagnosing these problems, using tools like logs, performance monitoring, and error messages, as well as providing solutions such as recalibrating configurations, optimizing server resources, or updating software. A proactive approach to NLB management can significantly enhance service uptime and user experience.
What is a Network Load Balancer?
A Network Load Balancer (NLB) is a crucial component in modern network architectures. It operates at the transport layer (Layer 4) of the OSI model, distributing incoming network traffic across multiple servers to ensure the reliability, scalability, and performance of web applications. Unlike traditional load balancers that handle HTTP or HTTPS traffic, an NLB efficiently manages non-HTTP protocols such as TCP, UDP, and TLS. This makes it ideal for applications requiring high availability and low latency, such as gaming servers, financial applications, and IoT services.
How Does a Network Load Balancer Work?
Network Load Balancers utilize algorithms like Round Robin, Least Connections, and IP Hash to distribute traffic. When a client sends a request, the NLB evaluates the incoming data packet and routes it to an appropriate backend server based on the selected algorithm. This process ensures that no single server gets overwhelmed by traffic. Furthermore, NLBs monitor the health of backend servers and automatically reroute traffic away from servers that are down, ensuring minimal service disruption. By balancing the traffic load, NLBs improve response times and prevent bottlenecks in high-demand environments.
Benefits of Using a Network Load Balancer
The use of a Network Load Balancer comes with numerous advantages. First and foremost, it ensures high availability by rerouting traffic to healthy servers, reducing the impact of server failures. Load balancing also enhances scalability, allowing businesses to add or remove servers based on demand without interrupting service. Another major benefit is improved performance, as NLBs reduce response times by efficiently distributing workloads. Additionally, NLBs often support SSL termination, offloading SSL decryption from backend servers, which frees up resources for application processing.
Key Features of a Network Load Balancer
A Network Load Balancer is equipped with a variety of features that make it a versatile solution for complex infrastructures. Some key features include TLS termination, which secures the traffic between clients and the load balancer, sticky sessions, where the load balancer keeps track of a user’s session, ensuring all requests are routed to the same backend server, and auto-scaling capabilities that allow the system to automatically adjust resources based on traffic spikes. DDoS protection is another critical feature that helps shield backend servers from malicious attacks, providing an added layer of security.
Network Load Balancer vs. Application Load Balancer: What’s the Difference?
The primary difference between a Network Load Balancer (NLB) and an Application Load Balancer (ALB) lies in the layer of the OSI model at which they operate. An NLB works at Layer 4 (Transport Layer), making it more suitable for non-HTTP traffic and protocols like TCP, UDP, and TLS. On the other hand, an ALB operates at Layer 7 (Application Layer), handling HTTP/HTTPS traffic and providing advanced features such as content-based routing, host-based routing, and SSL offloading. While both load balancers share the goal of improving performance and availability, choosing between them depends on the specific needs of your application and traffic type.
Use Cases for Network Load Balancers
Network Load Balancers are employed in a variety of use cases across different industries. They are particularly well-suited for applications requiring low latency and high throughput, such as online gaming platforms, VoIP services, and financial transaction systems. NLBs are also critical for high-performance computing environments, where distributed applications require seamless traffic distribution to optimize resource utilization. Additionally, NLBs are ideal for handling unpredictable traffic patterns, such as those seen in cloud-based services and microservices architectures, where scalability and reliability are paramount.
How to Implement a Network Load Balancer in Your Infrastructure?
Implementing a Network Load Balancer involves a few key steps. First, determine your traffic requirements and decide on the type of NLB that suits your needs (e.g., a cloud-based NLB like AWS NLB or an on-premise solution). Next, configure the backend servers, ensuring they are properly secured and optimized for performance. After setting up the NLB, integrate monitoring tools to track traffic flow, server health, and system performance. Finally, ensure failover configurations are in place, so the NLB can redirect traffic to healthy servers if any fail. This process will help maintain system uptime and ensure high availability.
Conclusion
Network Load Balancers play a pivotal role in the performance, scalability, and security of modern network infrastructures. By efficiently distributing traffic, they ensure high availability and prevent server overloads. With their ability to support various protocols and integrate seamlessly into cloud-based and on-premise environments, NLBs are indispensable for businesses looking to maintain fast, secure, and reliable services. As traffic demands increase and applications evolve, leveraging a Network Load Balancer becomes an essential strategy for maintaining optimal system performance and user experience.
0 notes
Text
What is the TCP protocol? The “Reliable Transmission Tool” of the Web
When you send emails, browse web pages or download files on the Internet, there is a key network protocol working behind the scenes, that is, the TCP protocol, which is widely used in a variety of Internet services, and it provides us with stable and reliable data transmission. The following will bring you a deeper understanding of the TCP protocol and how it works.

1. What is the TCP protocol?
TCP (Transmission Control Protocol) is a connection-oriented transport layer protocol that is responsible for ensuring the reliable and orderly transmission of data in a network.TCP is commonly used in applications that need to ensure the accuracy and integrity of data, such as web browsing, email, file transfer, etc. TCP is a protocol that is used in a wide variety of Internet services.
Simply put, the TCP protocol enables data to be transmitted from the sender to the receiver accurately and without error by establishing a reliable connection and ensuring the order and integrity of the data.
2. Key features of the TCP protocol
There are several important features of the TCP protocol that make it useful in data transmission where high reliability is required:
Connection-oriented: Before transmitting data, TCP needs to establish a connection between the two ends of the communication. This process is accomplished through a “three handshakes” mechanism, which ensures that both parties are ready to communicate.
Reliable Transmission: TCP ensures that each packet reaches the receiver successfully by means of an acknowledgement mechanism. If a packet is lost or corrupted, TCP automatically retransmits the packet.
Flow Control: TCP has a flow control mechanism that adjusts the speed of data transmission according to network conditions to avoid network congestion.
Congestion Control: TCP is able to detect congestion in the network and reduce the speed of data transmission to reduce the network load so as to avoid packet loss.
Orderly transmission: TCP ensures that packets reach the receiver in the correct order, even if they are transmitted in a different order in the network.
3. How the TCP protocol works
The core process of the TCP protocol can be divided into three phases: connection establishment, data transfer and connection termination.
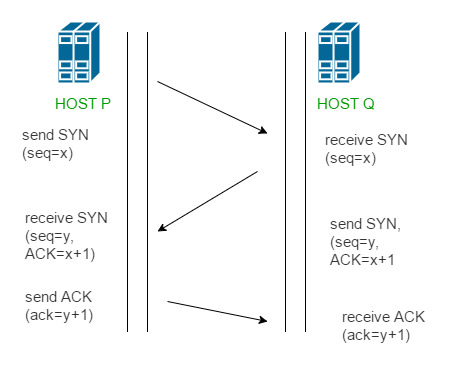
Connection Establishment: Three Handshakes
Before data transmission begins, TCP uses “three handshakes” to establish a connection:
1. First handshake: The client sends a connection request SYN (synchronization) packet to the server, indicating that it wishes to establish a connection.
2. Second handshake: The server receives the SYN packet and sends a packet with SYN and ACK (acknowledgement), indicating that it agrees to establish a connection.
3. Third handshake: the client receives a SYN-ACK packet from the server and sends an ACK packet with an acknowledgement, at which point the connection is established and data transfer can begin.
Data Transmission
During data transmission, TCP splits large data into smaller packets for transmission and assigns a sequence number to each packet. The receiver sends an acknowledgement message after receiving the packet. If the sender does not receive the acknowledgment message within the specified time, it retransmits the unacknowledged packet.
Connection Termination: Four Waves
After the data transfer is completed, TCP uses “four waves” to close the connection:
1. First wave: the sender sends a FIN (termination) packet, indicating that no more data will be sent.
2. The second wave: the receiver receives the FIN packet, send an ACK packet to confirm.
3. Third wave: the receiver sends its own FIN packet, indicating that data reception is complete.
4. Fourth wave: the sender receives the FIN packet, sends an ACK packet to confirm that the connection is terminated.
The TCP protocol ensures that our data transmission over the network is stable and orderly through mechanisms such as connection establishment, reliable transmission, and flow control. If you need to deal with demanding network applications in your work or life, TCP protocol is undoubtedly your trusted choice.
Meanwhile, if you need to further improve the stability and security of data transmission, it is recommended to use 711Proxy proxy service, which is able to provide worldwide quality IP resources, guaranteeing you a smoother and more unobstructed network connection.
0 notes
Text
DDoS Attack: The Most Prevalent Threat in the Digital Landscape
Understanding Distributed Denial of Service (DDoS) Attacks: An In-Depth AnalysisIntroduction to DDoS Attacks Mechanisms Behind DDoS AttacksKey Attack Vectors in DDoS Attacks Common Denominator: Resource Exhaustion The Impact of DDoS AttacksFinancial Losses Reputation Damage Operational Disruption Strategies for Mitigating DDoS Attacks Legal Strategies to Defend a Victim of a DDoS Attack1. Gathering and Preserving Evidence 2. Legal Claims and Remedies 3. Collaboration with Law Enforcement Consequences for the Perpetrators Proving a DDoS Attack and Identifying the Perpetrators1. Technical Evidence 2. Legal Identification of Perpetrators Understanding Distributed Denial of Service (DDoS) Attacks: An In-Depth Analysis Introduction to DDoS Attacks Distributed Denial of Service (DDoS) attacks have emerged as one of the most disruptive and prevalent threats in the digital landscape. Unlike traditional cyberattacks that focus on breaching security defenses to access sensitive information, DDoS attacks aim to disrupt services, making them inaccessible to legitimate users. This is achieved by overwhelming the target system with a massive influx of traffic, effectively paralyzing its operations.

Mechanisms Behind DDoS Attacks Distributed Denial of Service (DDoS) attacks are executed using a coordinated network of compromised devices, known as a botnet. This network typically comprises thousands, or even millions, of devices that have been infected with malware, enabling attackers to control them remotely. The primary goal of a DDoS attack is to inundate a target system with an overwhelming amount of traffic, thereby denying legitimate users access to the service. Key Attack Vectors in DDoS Attacks The traffic in a DDoS attack can manifest through several methods, each exploiting different aspects of network communication. The most common types include: - HTTP Floods: - Description: This method involves bombarding a web server with a massive number of HTTP requests. The objective is to overwhelm the server's ability to process incoming requests, making it unresponsive to legitimate users. - Mechanism: Attackers typically use botnets to send HTTP GET or POST requests, which are common methods for fetching resources or submitting data. The high volume of requests saturates the server's processing capacity, leading to a denial of service. - UDP Floods: - Description: UDP floods focus on the User Datagram Protocol (UDP), which is a connectionless protocol. This type of attack sends large quantities of UDP packets to random ports on the target system, causing the system to repeatedly check for applications listening on those ports. - Mechanism: Since UDP is a stateless protocol, the target must respond to each incoming packet with an ICMP (Internet Control Message Protocol) packet, reporting that the port is unreachable if there is no service listening on that port. This process consumes significant bandwidth and processing power, eventually exhausting the target's resources. - SYN Floods: - Description: SYN floods exploit the TCP handshake process, a fundamental part of establishing a TCP connection between a client and a server. This attack method involves sending a succession of TCP/SYN requests to initiate connections with the target server. - Mechanism: In a typical TCP handshake, a client sends a SYN request to the server, which responds with a SYN-ACK, and then the client sends an ACK to establish the connection. In a SYN flood, the attacker sends a flood of SYN requests without completing the handshake, leaving the server waiting for the final ACK. These half-open connections consume resources and can quickly exhaust the server's ability to establish new connections, leading to a denial of service. Common Denominator: Resource Exhaustion The unifying factor in these attack vectors is their ability to exhaust the target's critical resources—be it bandwidth, CPU power, or memory. By overwhelming these resources, DDoS attacks prevent the target system from functioning normally, thereby denying service to legitimate users. The efficiency and scale of these attacks are largely dependent on the size and sophistication of the botnet, as well as the specific attack method employed. In summary, the mechanisms behind DDoS attacks are designed to exploit the limitations of network protocols and system resources. By understanding these mechanisms, organizations can better prepare for and mitigate the impact of such attacks, ensuring the continued availability and security of their services. The Impact of DDoS Attacks Distributed Denial of Service (DDoS) attacks pose significant risks to organizations by disrupting access to essential online services. The ramifications of these attacks extend far beyond temporary inconveniences, often resulting in severe and lasting consequences. The impact of a successful DDoS attack can be categorized into three primary areas: financial losses, reputation damage, and operational disruption. Financial Losses One of the most immediate and tangible effects of a DDoS attack is the financial loss incurred due to downtime. For businesses that depend on digital platforms for their operations, such as e-commerce websites, financial institutions, and online service providers, even brief periods of unavailability can lead to substantial revenue losses. The specific financial impact can vary widely depending on the nature of the business and the duration of the outage. Key factors contributing to financial losses include: - Lost Sales: In e-commerce, downtime translates directly to lost sales opportunities, as customers are unable to complete transactions. - Operational Costs: Businesses may incur additional costs for IT support, security measures, and emergency response to mitigate the attack and restore services. - Penalties and Legal Costs: In some industries, regulatory requirements mandate minimum service availability. Failure to comply can result in penalties, fines, or legal action from affected parties. Reputation Damage The reputational impact of a DDoS attack can be profound and long-lasting. In an era where customer trust and brand reliability are critical, repeated or prolonged service outages can severely damage a company's reputation. The erosion of trust can manifest in several ways: - Customer Dissatisfaction: Users may become frustrated and lose confidence in a service's reliability, leading to customer churn and negative word-of-mouth. - Brand Perception: A high-profile service disruption can attract media attention, painting the affected company as vulnerable and poorly secured. This negative publicity can tarnish the brand's image and deter potential customers or partners. - Investor Confidence: For publicly traded companies, service outages can negatively impact stock prices as investor confidence wanes. The perceived inability to protect against cyber threats can lead to a loss of market value. Operational Disruption The operational impacts of DDoS attacks can be particularly severe for organizations that provide critical services, such as healthcare providers, government agencies, and utilities. In these cases, the disruption extends beyond financial implications and can have serious consequences for public safety and welfare. Key aspects of operational disruption include: - Service Availability: Critical systems, such as emergency services, healthcare platforms, or public infrastructure, may become unavailable, potentially putting lives at risk. - Data Integrity and Security: While DDoS attacks primarily focus on disrupting service availability, they can also serve as a distraction for other malicious activities, such as data breaches or malware deployment. This can compromise the integrity and security of sensitive information. - Resource Allocation: Organizations may need to divert significant resources, both human and technical, to respond to and recover from an attack. This can strain internal capabilities and delay other essential operations or projects. The impact of DDoS attacks is multifaceted, affecting financial stability, brand reputation, and operational continuity. The extent of the damage often depends on the organization's preparedness and the effectiveness of its response measures. As cyber threats continue to evolve, it is crucial for organizations to implement robust security protocols, develop comprehensive incident response plans, and invest in advanced DDoS mitigation technologies. By doing so, businesses can better safeguard against the detrimental effects of these attacks and ensure the continuous availability of their critical services. Strategies for Mitigating DDoS Attacks To protect against DDoS attacks, organizations must adopt a comprehensive, multi-layered defense strategy: - Advanced Network Security Solutions: - Intrusion Detection Systems (IDS): These systems monitor network traffic for suspicious activity and can alert administrators of potential attacks. - Web Application Firewalls (WAF): WAFs provide an additional layer of protection by filtering and monitoring HTTP traffic between a web application and the internet. - DDoS Protection Services: Specialized services can detect and mitigate DDoS attacks in real-time, absorbing and filtering malicious traffic before it reaches the target. - Scalable Infrastructure: - Content Delivery Networks (CDN): CDNs distribute traffic across a network of servers, reducing the load on the primary server and mitigating the impact of a DDoS attack. - Cloud-Based Solutions: Cloud services can dynamically scale resources to handle traffic surges, providing additional resilience against large-scale attacks. - Rate Limiting and Traffic Filtering: - Rate Limiting: This technique limits the number of requests a server will accept in a given timeframe, preventing overload from excessive traffic. - Traffic Filtering: Implementing filters to block traffic from known malicious IP addresses or patterns can reduce the risk of a successful attack. - Incident Response Plan: - An effective incident response plan outlines the steps to be taken in the event of a DDoS attack, including communication protocols, mitigation strategies, and service restoration processes. Having a clear plan helps minimize downtime and ensures a swift recovery. Legal Strategies to Defend a Victim of a DDoS Attack Defending a victim of a Distributed Denial of Service (DDoS) attack involves a multifaceted approach that includes legal strategies, technical evidence gathering, and collaboration with law enforcement and cybersecurity experts. The primary objectives are to establish the occurrence and impact of the attack, identify the perpetrators, and seek legal redress or protection. Here are key strategies: 1. Gathering and Preserving Evidence Digital Forensics: Immediately after a DDoS attack, it is crucial to collect and preserve digital evidence. This includes logs, network traffic data, server response times, and any anomalous patterns observed during the attack. Digital forensics experts can analyze this data to trace the origin of the attack and identify the involved devices and methods. Chain of Custody: Maintaining a clear chain of custody for all evidence ensures that it is admissible in court. This involves documenting how evidence was collected, stored, and handled, preventing any tampering or loss. Expert Testimony: Cybersecurity experts can provide testimony on the nature of the DDoS attack, its impact on the victim's systems, and the methods used by the attackers. This expert testimony is critical in explaining complex technical details to a court. 2. Legal Claims and Remedies Criminal Prosecution: If the perpetrators are identified, they can be prosecuted under various cybercrime laws. In many jurisdictions, launching a DDoS attack is a criminal offense, punishable by fines, imprisonment, or both. The severity of the punishment often depends on the extent of the damage and whether the attack was part of a larger criminal enterprise. Civil Litigation: Victims may pursue civil litigation against the perpetrators or any entities that facilitated the attack (e.g., internet service providers, if negligence can be proven). Claims can include compensation for financial losses, damage to reputation, and costs incurred due to the attack. Injunctions: Victims can seek injunctive relief to prevent ongoing or future attacks. This may involve court orders compelling service providers to block certain traffic or requiring parties to cease specific activities. 3. Collaboration with Law Enforcement Reporting and Cooperation: Victims should report the DDoS attack to relevant law enforcement agencies. In many cases, agencies such as the FBI's Cyber Crime Division or Europol's European Cybercrime Centre have the resources to investigate large-scale cybercrimes. Information Sharing: Sharing information with law enforcement can assist in identifying and prosecuting the attackers. This includes details about the attack vectors, botnets involved, and any ransom demands made (if applicable). Consequences for the Perpetrators The consequences for individuals convicted of launching or orchestrating a DDoS attack vary by jurisdiction but can include: Criminal Penalties: These often involve imprisonment, especially if the attack caused significant disruption or was aimed at critical infrastructure. Penalties can also include substantial fines, community service, and probation. Civil Liability: In addition to criminal penalties, perpetrators may face civil lawsuits from victims seeking compensation for damages. This can lead to financial restitution orders, forcing the perpetrators to pay for losses incurred due to the attack. Asset Seizure: In cases where DDoS attacks were part of a broader criminal enterprise, authorities may seize assets obtained through illegal activities. Proving a DDoS Attack and Identifying the Perpetrators Proving a DDoS attack and identifying the individuals responsible involves a combination of technical and legal steps: 1. Technical Evidence Network and Server Logs: These logs can show a sudden spike in traffic, identify IP addresses from which the traffic originated, and highlight unusual patterns that are consistent with a DDoS attack. Traffic Analysis: Analyzing the nature and volume of incoming traffic can reveal the type of DDoS attack (e.g., HTTP flood, UDP flood). Patterns such as consistent traffic from certain regions or the use of particular protocols can help in pinpointing the source. Botnet Analysis: Identifying the botnet used can provide clues to the attack's origin. This involves tracking command and control servers, often requiring international cooperation due to the global nature of botnets. 2. Legal Identification of Perpetrators IP Tracing: While attackers often use techniques like IP spoofing to hide their identities, sophisticated tracing methods can sometimes reveal the true source of the traffic. However, this is often challenging and may require cooperation from ISPs and international agencies. Subpoenas and Warrants: Law enforcement can use legal tools like subpoenas and warrants to obtain information from service providers, such as logs or customer data, that can help identify the attackers. Digital Footprints: Sometimes, attackers leave behind digital footprints, such as communications on forums, use of specific software tools, or even ransom notes. These can be used to link the attack to specific individuals or groups. The legal defense of a DDoS attack victim requires a comprehensive strategy that includes evidence gathering, collaboration with authorities, and potentially pursuing criminal and civil remedies. The consequences for perpetrators can be severe, including criminal penalties and civil liabilities. Proving the occurrence of a DDoS attack and identifying those responsible is a complex process that relies on both technical expertise and legal mechanisms. This integrated approach is essential for ensuring accountability and protecting victims' rights. As cyber threats continue to evolve, the importance of robust defenses against DDoS attacks cannot be overstated. Businesses must be proactive in implementing security measures and preparing for potential incidents. Collaborating with internet service providers (ISPs) and cybersecurity experts can further enhance defenses, ensuring the availability and reliability of critical services. By adopting these strategies, organizations can mitigate the risks associated with DDoS attacks and safeguard their digital assets and reputation. https://www.youtube.com/watch?v=a_r-lzQKMAQ Read the full article
0 notes
Text
TCP handshake error causes and solutions
A TCP handshake error occurs when the three-way handshake process, which is essential for establishing a TCP connection, fails. This handshake involves three steps: SYN (synchronize) packet sent by the client. SYN-ACK (synchronize-acknowledge) packet sent by the server. ACK (acknowledge) packet sent by the client. If any part of this handshake fails, the connection cannot be established. Here…
View On WordPress
0 notes
Text
what is vpn port number
🔒🌍✨ Get 3 Months FREE VPN - Secure & Private Internet Access Worldwide! Click Here ✨🌍🔒
what is vpn port number
VPN port numbers explained
When using a VPN (Virtual Private Network) to secure your internet connection and protect your online privacy, understanding VPN port numbers becomes essential for optimizing your VPN experience.
VPN port numbers are specific communication endpoints used by VPN protocols to establish secure connections between devices. VPN protocols, such as OpenVPN, L2TP/IPsec, and IKEv2, utilize different port numbers to facilitate data transmission over the internet securely.
OpenVPN, one of the most popular VPN protocols, typically uses port number 1194 for UDP and port 443 for TCP connections. L2TP/IPsec protocol commonly operates on UDP port 500, UDP port 4500, and IP protocol 50. IKEv2 protocol often runs on UDP port 500 for the initial handshake and UDP port 4500 for encrypted data transmission.
Understanding VPN port numbers is crucial for troubleshooting connectivity issues, optimizing network performance, and ensuring seamless VPN operation. If you encounter connection problems, checking if the required VPN port numbers are open on your network firewall or router settings can help resolve the issue.
In conclusion, VPN port numbers play a vital role in the secure and efficient operation of VPN services. By familiarizing yourself with the port numbers associated with different VPN protocols, you can enhance your online security and privacy while enjoying a seamless VPN experience.
Understanding VPN protocols and port numbers
A Virtual Private Network (VPN) is a critical tool for ensuring privacy and security when browsing the internet. It allows users to create a secure connection to another network over the internet, encrypting their data and masking their online activities. To establish this secure connection, VPNs utilize various protocols and port numbers.
VPN protocols are sets of rules determining how data is transmitted between devices within a VPN connection. There are several VPN protocols available, each with its strengths and weaknesses. Some of the most common VPN protocols include OpenVPN, L2TP/IPsec, PPTP, and IKEv2/IPsec.
OpenVPN is widely regarded as one of the most secure and versatile VPN protocols, offering excellent encryption and stability. L2TP/IPsec is another popular choice known for its strong security features, although it may not be as fast as other protocols. PPTP, while fast and easy to set up, is considered less secure than other protocols and is not recommended for sensitive data transmission. IKEv2/IPsec is another secure option that provides excellent speed and reliability.
Port numbers are used to direct internet traffic to specific devices within a network. When setting up a VPN connection, different protocols utilize different port numbers to facilitate communication. For example, OpenVPN typically uses port 1194, while L2TP/IPsec commonly uses ports 500 and 4500. Understanding which port numbers are associated with each protocol is crucial for configuring firewalls and routers to allow VPN traffic to pass through.
In conclusion, understanding VPN protocols and port numbers is essential for optimizing the security and performance of your VPN connection. By selecting the right protocol and configuring the appropriate port numbers, you can enjoy a safe and efficient browsing experience while protecting your sensitive data online.
Types of VPN port numbers and their functions
Virtual Private Networks (VPNs) utilize various port numbers to facilitate secure communication between devices and servers. Understanding the different types of VPN port numbers and their functions is crucial for optimizing network security and performance.
UDP Port 500 (IKE):
Internet Key Exchange (IKE) uses UDP port 500 for establishing secure connections between VPN clients and servers. It initiates the negotiation process for setting up the VPN tunnel.
TCP Port 1723 (PPTP):
Point-to-Point Tunneling Protocol (PPTP) employs TCP port 1723 to encapsulate VPN data within IP packets. PPTP is one of the oldest VPN protocols and is commonly supported by various operating systems.
UDP Port 1701 (L2TP):
Layer 2 Tunneling Protocol (L2TP) relies on UDP port 1701 for establishing tunnels between VPN endpoints. L2TP doesn't provide encryption itself but is often combined with IPsec for enhanced security.
TCP Port 443 (SSL/TLS):
Secure Sockets Layer (SSL) and its successor Transport Layer Security (TLS) utilize TCP port 443 for secure HTTPS connections. Many VPN services offer SSL/TLS-based VPNs, enabling users to bypass firewalls that restrict other VPN protocols.
UDP and TCP Ports 1194 (OpenVPN):
OpenVPN, a versatile and highly configurable VPN protocol, can operate over both UDP and TCP ports 1194. It offers robust encryption and is known for its flexibility in various network environments.
UDP and TCP Ports 500 and 4500 (IPsec):
Internet Protocol Security (IPsec) utilizes UDP ports 500 and 4500 for securing IP communications. It offers strong encryption and authentication, making it suitable for enterprise-level VPN deployments.
Understanding these VPN port numbers and their associated protocols can help network administrators troubleshoot connectivity issues, configure firewall rules, and optimize VPN performance based on specific requirements and security considerations.
Securing VPN connections with port numbers
In order to enhance the security of VPN connections, one effective method is to utilize specific port numbers. VPN protocols such as PPTP, L2TP, and OpenVPN rely on certain port numbers to establish a connection between the user's device and the VPN server.
By configuring VPN connections to operate on non-standard port numbers, users can add an extra layer of security to their communications. This practice helps to obscure VPN traffic and make it more difficult for potential attackers to identify and intercept the connection.
For example, traditional VPN protocols like PPTP commonly use port 1723, while L2TP typically operates on UDP ports 500 and 4500. OpenVPN, a popular open-source VPN protocol, can be configured to run on a variety of ports, offering flexibility in customization.
When selecting port numbers for VPN connections, it is essential to choose ports that are not commonly associated with other services or applications to avoid potential conflicts and ensure smooth connectivity. Additionally, regularly changing port numbers can help prevent unauthorized access and enhance the overall security of VPN connections.
Overall, securing VPN connections with port numbers is a proactive measure that reinforces the protection of sensitive data and communications, making it increasingly challenging for malicious entities to compromise the integrity and confidentiality of the connection. By incorporating this practice into VPN configurations, users can bolster their online privacy and security efforts.
Configuring VPN port numbers for optimal security
Configuring VPN port numbers for optimal security is a crucial aspect of safeguarding your online activities and data. VPNs, or Virtual Private Networks, encrypt your internet connection, ensuring that your browsing, communications, and sensitive information remain secure from prying eyes. However, selecting the right port numbers can further enhance this security.
When setting up a VPN, you typically have the option to choose from a range of port numbers through which your VPN connection will operate. While many users opt for the default port assigned by their VPN provider, it's essential to consider the security implications of this choice.
One strategy for enhancing security is to avoid using well-known or commonly used port numbers. Cybercriminals often target these ports, making them more vulnerable to attacks. Instead, opting for non-standard or higher-numbered ports can help obscure your VPN traffic, making it more challenging for potential attackers to identify and intercept.
Additionally, some VPN protocols offer greater security than others. For example, OpenVPN is widely regarded as one of the most secure VPN protocols available, offering robust encryption and authentication mechanisms. When configuring your VPN, selecting a port number compatible with your chosen protocol is essential for ensuring optimal security.
Furthermore, regularly updating and monitoring your VPN configuration is essential for maintaining security. As new threats emerge and security vulnerabilities are discovered, adjusting your port numbers and protocols accordingly can help mitigate risks and keep your data safe.
In conclusion, configuring VPN port numbers for optimal security involves selecting non-standard ports, choosing secure protocols like OpenVPN, and staying vigilant against emerging threats. By taking these steps, you can bolster the security of your VPN connection and protect your online privacy and sensitive information effectively.
0 notes